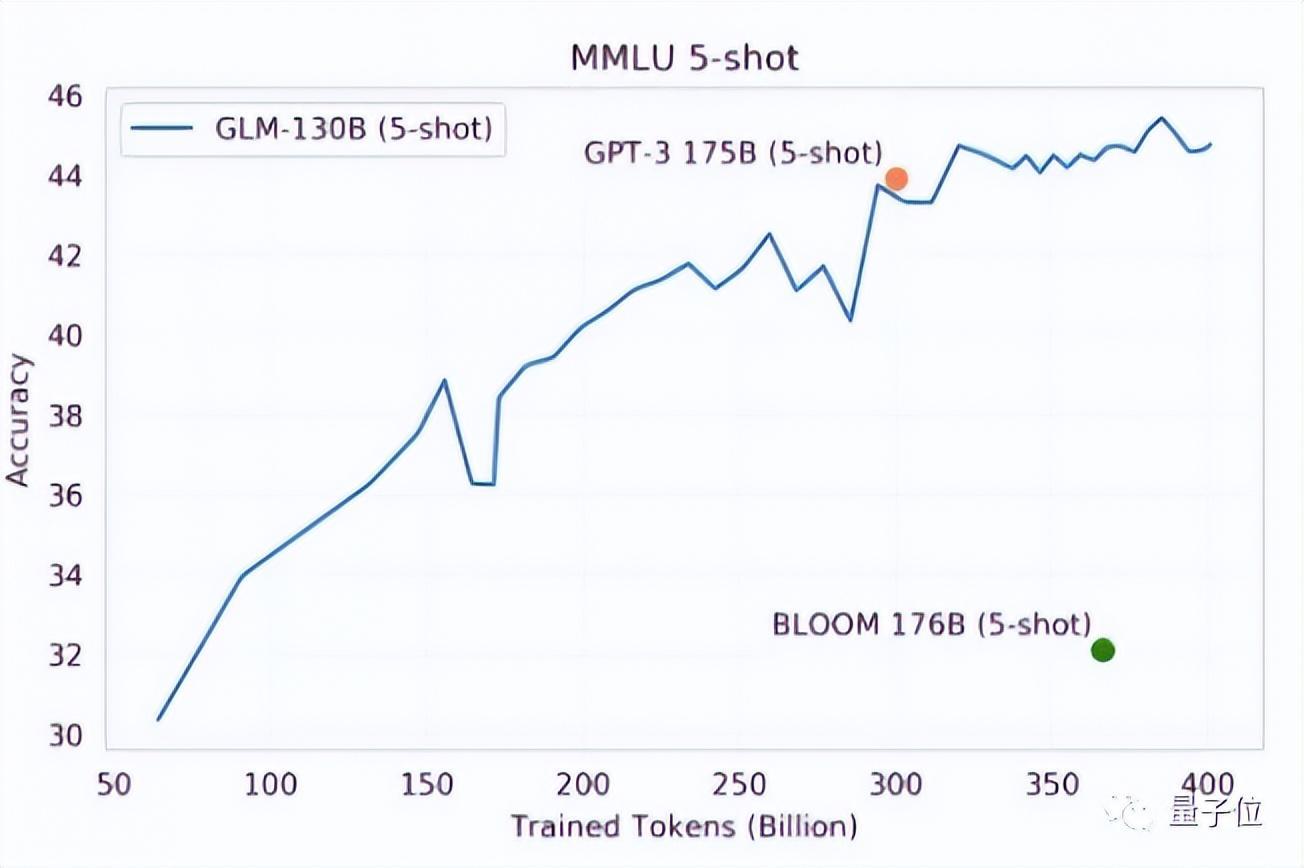
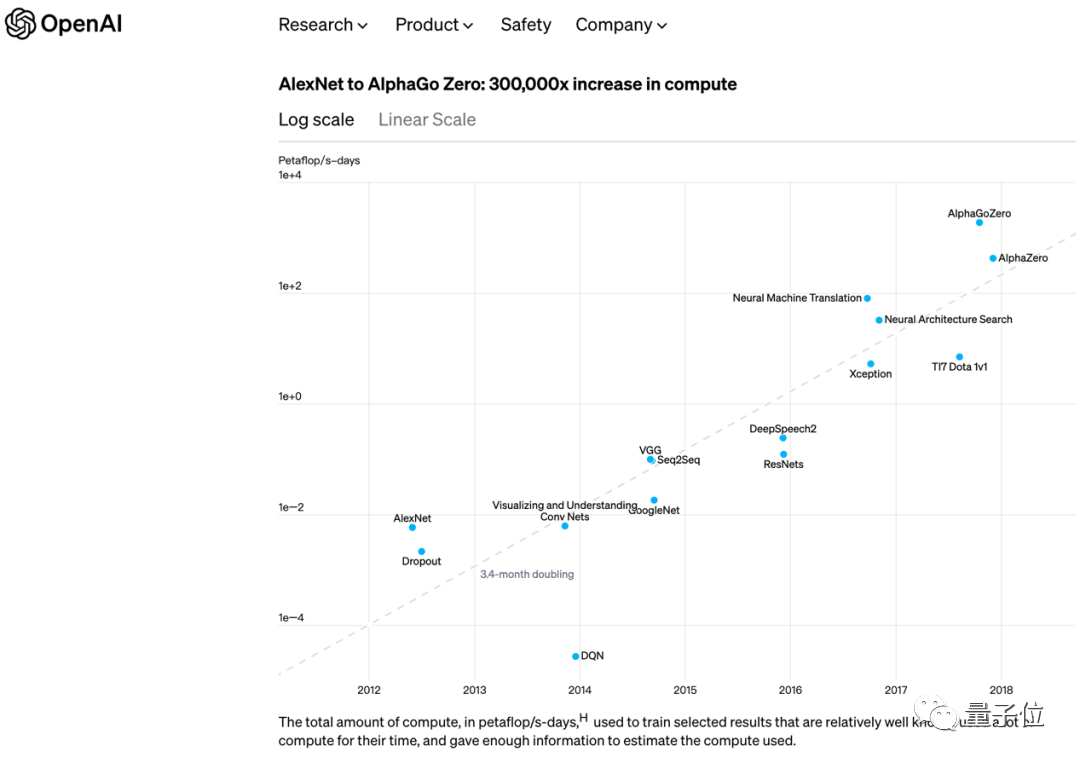
1
3
新手上路
衡宇 发自 凹非寺 量子位 | 公众号 QbitAI
自2012年以来,AI训练任务所运用的算力每3.43个月就会翻倍。到2018年,AI算力需求增长了30万倍。
使用道具 举报
0
2
8
11
6
5
4
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|新宇
GMT+8, 2025-7-3 21:03 , Processed in 0.095331 second(s), 19 queries .
Powered by Discuz! X3.4 技术支持:迪恩网络
© 2001-2013 Comsenz Inc.



 发表于 2023-3-25 20:54:22
发表于 2023-3-25 20:54:22